
DataOutputStream、DataInputStream可以将Java中的基本类型以类似对象的方式存储或读取,不再以字节方式处理,方法非常简单。但在处理中文字符时,存储方式就比较特殊。
基本类型的定长读写
Java基本类型都是定长的,也就是每个基本类型通过DataInputStream写入文件时,都是定长地写。在DataInputStream读取时不需要程序员考虑下一个类型从何处开始何处结束。比如整型为32位4字节长,浮点型为32位4字节长,boolean型非常特殊,有效值只是1个bit(0或1),size在官方JVM规范中也没有明确讲明,但在例子中可以看到它占用8位1个字节。
基本类型的读写非常简单,读的顺序必须和写的顺序保持一致。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// write primitive data
try(DataOutputStream doStream = new DataOutputStream(new FileOutputStream("data1.bin"))){
doStream.writeInt(123); // employee id
doStream.writeFloat(3000.45F); // salary
doStream.writeBoolean(true); // active user
}catch(Exception e){
//
}
// read
try(DataInputStream diStream = new DataInputStream(new FileInputStream("data1.bin"))){
System.out.println(diStream.readInt());
System.out.println(diStream.readFloat());
System.out.println(diStream.readBoolean());
}catch(Exception e){
//
}
如果用十六进制工具打开这个文件,可以很容易分析出文件数据的结构。

- 整型123,占用4个字节。
- 浮点3000.45F,占用4字节
- boolean型,占用1字节
所以,写入上述三个数据类型,文件大小为9字节。
中文字符的存储表达
读写中文字符时,处理比较特殊。中文字符一般使用定长的unicode或者变长的UTF-8来处理,但使用不同的方法,字节保存方式悬殊很大。
writeByte和writeBytes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// write one byte
try(DataOutputStream doStream = new DataOutputStream(new FileOutputStream("data20.bin"))){
doStream.writeByte('h');
doStream.writeByte('中');
}catch(Exception e){
//
}
// read one byte
try(DataInputStream diStream = new DataInputStream(new FileInputStream("data20.bin"))){
byte b1 = diStream.readByte();
byte b2 = diStream.readByte();
System.out.println((char)b1);
System.out.println((char)b2);
}catch(Exception e){
//
}
类似地,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// write bytes
try(DataOutputStream doStream = new DataOutputStream(new FileOutputStream("data21.bin"))){
doStream.writeBytes("hi");
doStream.writeBytes("中国");
}catch(Exception e){
//
}
// read bytes
try(DataInputStream diStream = new DataInputStream(new FileInputStream("data21.bin"))){
byte[] b1 = new byte[1024];
int r1 = diStream.read(b1);
System.out.println(new String(b1, 0, r1));
}catch(Exception e){
//
}
writeBytes的写方法其实循环地写writeByte,写入的是以字节为单位。对于中文字符而言,一个中文字符在Unicode里需要2个字节用16位标识,比如“中”的16进制标识就是4E2D(可以通过查看表格查询中文Unicode编码集),在使用writeByte写入的时候,由于只能写1个字节,因此会舍去高八位,只保留低八位,所以会写入2D,同样,“国”的十六进制为56FD,只会写入FD。
因此使用writeByte或者writeBytes写入的中文字符,再用readByte或者read读取时,因为高八位已经被丢失,所以读出来就是乱码。所以,如果查看这2个文件的十六进制数据,会发现中文字符的高八位均不存在了。

writeChar和writeChars
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// write one char
try(DataOutputStream doStream = new DataOutputStream(new FileOutputStream("data22.bin"))){
doStream.writeChar('h');
doStream.writeChar('中');
}catch(Exception e){
//
}
// read one char
try(DataInputStream diStream = new DataInputStream(new FileInputStream("data22.bin"))){
char c1 = diStream.readChar();
System.out.println(c1);
char c2 = diStream.readChar();
System.out.println(c2);
}catch(Exception e){
//
}
换个方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// write chars
try(DataOutputStream doStream = new DataOutputStream(new FileOutputStream("data23.bin"))){
doStream.writeChars("hi");
doStream.writeChars("中国");
}catch(Exception e){
//
}
// read chars
try(DataInputStream diStream = new DataInputStream(new FileInputStream("data23.bin"))){
char[] c1 = new char[4];
for (int i = 0; i < 4; i++) {
c1[i] = diStream.readChar();
}
System.out.println(c1);
char[] c2 = new char[2];
for (int i = 0; i < 2; i++) {
c2[i] = diStream.readChar();
}
System.out.println(c2);
}catch(Exception e){
//
}
writeChars和writeChar其实类似,都是以2个字节作为一个字符来写入,由于中文字符在unicode中是以2个字节存储的,所以能够完整地保留中文信息。但对于英文字符来说,2个字节标识一个英文字符属于浪费,因为英文只需要1个字节就能标识,多出来的高八位就只能用0来补足。
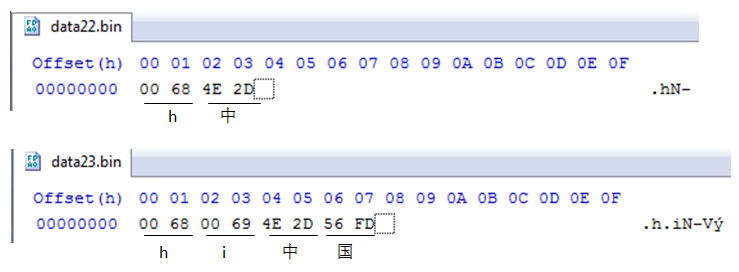
在这2个文件中,可以看到“中”被完整地保存为4E2D,而字符“h”则表示为0068,实际上只要一个字节即十六进制的68就能标识。0属于空间浪费。
writeUTF
如果比较char和byte类型的写,我们可能倾向于使用char方式,因为它能保存中文字符。但是使用writeChar(s)存在几个大的问题。
- writeChar(s)是以2个字节为单元存储一个字符,即16位,所以只能表示2^16=65536个字符,光中文字符就有10万多个,世界文字更多,所以2字节无法表示全世界文字。
- 当多个char和其他基本类型(比如int, boolean)等混写在一个文件中时,读取时必须事先知道当时写入了多少个字符,否则无法定位去读,所以不可预知。
- 对于英文字符(ASCII<255)而言,使用2字节存储,非常浪费。
因此,可以通过UTF-8(理论上能识别FFFFFF个字符)来标识。但在Java中,又对UTF-8计算方式做了适当的限定,只能识别65535个字符。它的详细规则为:
- 当字符c的十六进制编码在 0001和007f之间时,直接使用一个字节来标识,比如“h”的编码为0068,则只用一个字节表示。
当字符c的十六进制编码等于0000 或者在 0080和07ff之间时,使用2个字节标识,从高到低的字节分别表示为:
1 2
(byte)(0xc0 | (0x1f & (c >> 6))) (byte)(0x80 | (0x3f & c))
当字符c的十六进制编码在0800和ffff之间时,使用3字节编码,从高到低的字节分别表示为:
1 2 3
(byte)(0xe0 | (0x0f & (c >> 12))) (byte)(0x80 | (0x3f & (c >> 6))) (byte)(0x80 | (0x3f & c))
在使用writeUTF时,写每个字符之前,Java会写入2个字节的长度信息,再写入具体的用户数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// write UTF
try(DataOutputStream doStream = new DataOutputStream(new FileOutputStream("data24.bin"))){
doStream.writeUTF("hi");
doStream.writeUTF("中国");
}catch(Exception e){
//
}
// read UTF
try(DataInputStream diStream = new DataInputStream(new FileInputStream("data24.bin"))){
System.out.println(diStream.readUTF());
System.out.println(diStream.readUTF());
}catch(Exception e){
//
}

事实上,2个字节的长度信息,就是16位,它最多只能标识65536个文字,在上面的算法中,最多也是识别到ffff,即65535。可见, writeUTF并没有彻底解决列出的第一个问题,就是解决全世界文字。Java中这个只能由UTF-16去解决了,但DataOutputStream目前只能支持65535,并且当字符编码超过FFFF时,Java会抛出UTFDataFormatException错误。